Chapter 1.4 · 4 min read · May 5, 2026
LLM Tracing and Workflows
When one LLM call is not enough, you compose multiple calls into a workflow. Without LLM tracing, debugging is impossible. Tracing is how you see what your AI actually did.

By v0.5 your AI app is no longer one LLM call. A user asks a question, your code retrieves relevant documents, calls the LLM, maybe calls a tool to look up the customer's order, calls the LLM again, runs a verifier on the response, and finally replies. That is a workflow: a sequence of steps, some deterministic, some LLM-driven, that together produce one user-facing answer.
This section covers two related skills: how to compose a workflow, and how to actually see what happened inside one when it goes wrong.
What is a workflow
A workflow is a sequence of steps the system runs in a specific order to handle one user request. Steps can be:
- Deterministic: code you control. "Look up the customer's account." "Search the knowledge base."
- LLM-driven: the model produces text. "Generate a response from the retrieved context."
- Tool calls: the LLM decides to invoke a function (e.g. fetch an order, calculate something), the surrounding code runs the function, the result feeds back into the next LLM call.
A typical customer support workflow:
Six steps. Two are LLM calls (generate, verify). Four are deterministic.
Workflows are how real AI applications are built. Most products that look like "agents" are actually workflows with a fixed structure. (Section 6 covers when you need a true agent.)
Why one workflow is hard to debug
When a customer says "your AI told me my refund window was 60 days," you have to figure out:
- Which retrieval results fed the model (was the wrong KB article surfaced?)
- Which prompt version was deployed at that moment
- What the LLM generated before any post-processing
- Whether the verifier flagged it
- What the customer saw
Without a record of every step, you guess. You re-run the workflow on the same input and get a slightly different result because the model is non-deterministic. You spend a day trying to reproduce a 30-second customer interaction.
This is the problem tracing solves.
What is a trace
A trace is a record of one full user request, broken into nested steps called spans. A span is one unit of work: an LLM call, a retrieval query, a tool invocation, a deterministic step.
A trace from the workflow above:
support_request (workflow span, root)
├── authenticate_user (task span)
├── retrieve_kb (task span)
│ └── vector_search (tool span)
├── generate_response (task span)
│ └── chat.completions.create (LLM span, auto-instrumented)
├── verify_citations (task span)
│ └── chat.completions.create (LLM span)
└── decide_escalation (task span)
Each span captures: timestamps, inputs, outputs, model used, latency, tokens, prompt version, errors. Click a span in the dashboard, see exactly what happened.
When a customer reports a bad answer six months later, you find their trace by session ID, click the LLM span, and see the exact prompt, the exact retrieval candidates, and the exact response. You can replay the same call against a different prompt or model.
How to instrument a workflow
Most agent frameworks (LangChain, LlamaIndex, OpenAI Agents SDK, CrewAI, AutoGen) get auto-instrumented for free. For your own code, you mark span boundaries with decorators.
Respan's Python SDK uses four decorators:
@workflow: top-level boundary. One per user request.@task: a deterministic step inside a workflow.@agent: an LLM-decision boundary (used when the LLM decides next action; covered in section 6).@tool: an external function call (search, database query, API call).
from openai import OpenAI
from respan import Respan
from respan.decorators import workflow, task
Respan() # initialize once at app startup
client = OpenAI()
@task(name="retrieve_kb")
def retrieve_kb(query: str):
# your retrieval code (vector search, etc.)
return ["Article 1: Returns within 30 days", "Article 2: ..."]
@task(name="generate_response")
def generate_response(query: str, context: list[str]):
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Use the context to answer."},
{"role": "user", "content": f"Context: {context}\n\nQuestion: {query}"},
],
)
return completion.choices[0].message.content
@workflow(name="support_request")
def handle_support_request(query: str):
context = retrieve_kb(query)
return generate_response(query, context)
print(handle_support_request("How do I return a product?"))That code produces a trace tree like this:
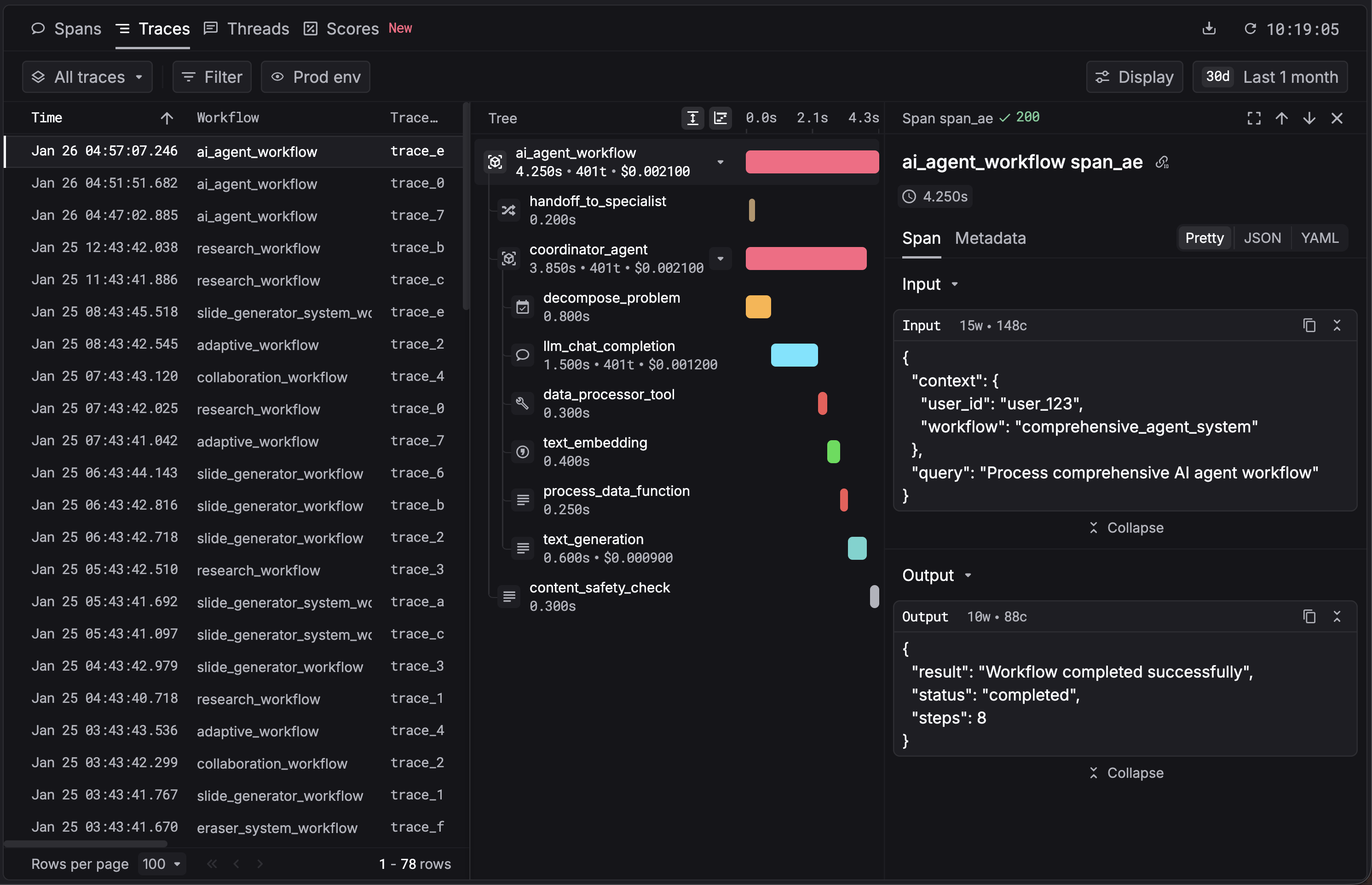
Each span is clickable. The LLM call inside generate_response shows up automatically because the SDK instruments OpenAI's client.
If you do not want to write decorators
The Respan CLI auto-instruments your project end-to-end:
npx @respan/cli setupThis uses your existing coding agent (Claude Code, Cursor, Codex) with a docs MCP attached. It detects your project layout, installs the SDK, and adds the decorators or framework hooks for you. Five minutes, no manual instrumentation.
What you have at the end of section 4
- Multi-step workflows that compose deterministic steps and LLM calls.
- A trace tree per request showing every step, with inputs, outputs, latency, tokens, and prompt versions.
- The ability to find any past response and replay it.
- An audit trail for compliance.
Next: measuring quality with evals
The next section, Measuring quality with evals, covers how to know if a change made things better, before customers find out the hard way.
Or back to the Chapter 1 hub.