Backstory: Building the World's First Self-Driving CRM
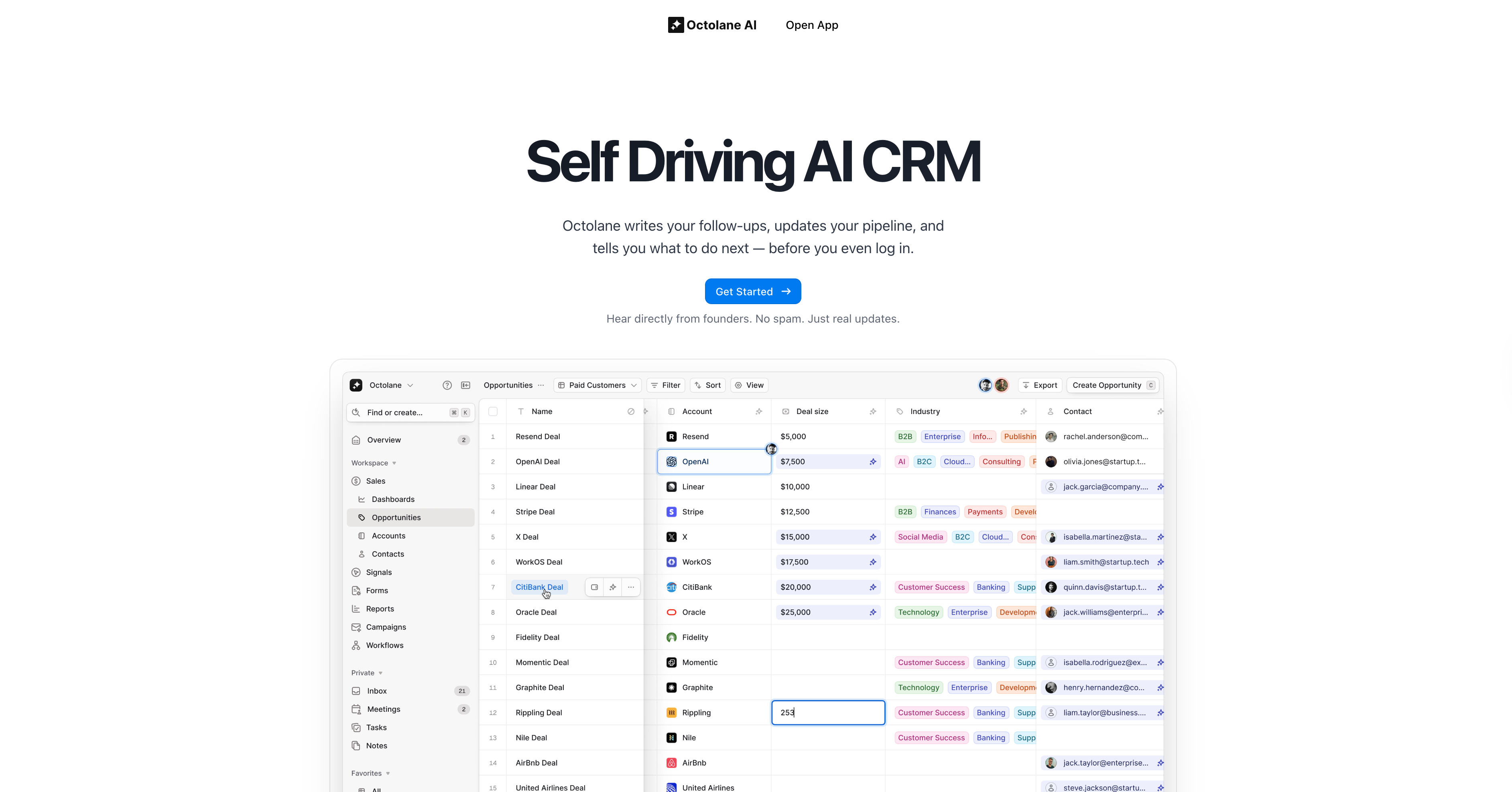
Octolane AI set out to eliminate sales busywork. Instead of reps manually logging notes, updating fields, or remembering follow-ups, Octolane automates it all. The CRM updates itself using email, calendar, and meeting data, and even recommends next actions.
After YC W24, Octolane grew fast. In April 2025, they raised a $2.6M oversubscribed seed round to help bring the first AI-native CRM to market (Forbes).
Turning Point: LLM Debug Debt Was Slowing Down Launch
"We were shipping fast, but any LLM error meant hours of manual backtracking. We needed to see exactly what the models were doing."
- Md Abdul Halim Rafi, CTO, Octolane AI
Octolane runs hundreds of LLM calls per user session, from identifying patterns in sales calls to enriching contact data and generating AI field updates. But without a clear view of prompt inputs, outputs, and token costs, the engineering team lost hours debugging every week.
They needed observability, without slowing down shipping velocity.
Solution: LLM Observability in 15 Minutes
The Octolane team dropped in the Respan proxy to their Next.js app. In minutes:
- Every LLM call, prompt, input, response, latency, token usage was auto-logged
- Slow calls and failures were surfaced in Slack instantly
- Prompt iterations were tracked with full history
- Costs were visible across models and endpoints
Inside the Workspace: Real-Time Debugging in Action
To show what this looks like in practice, here's a live screenshot from Octolane's workspace inside Respan:
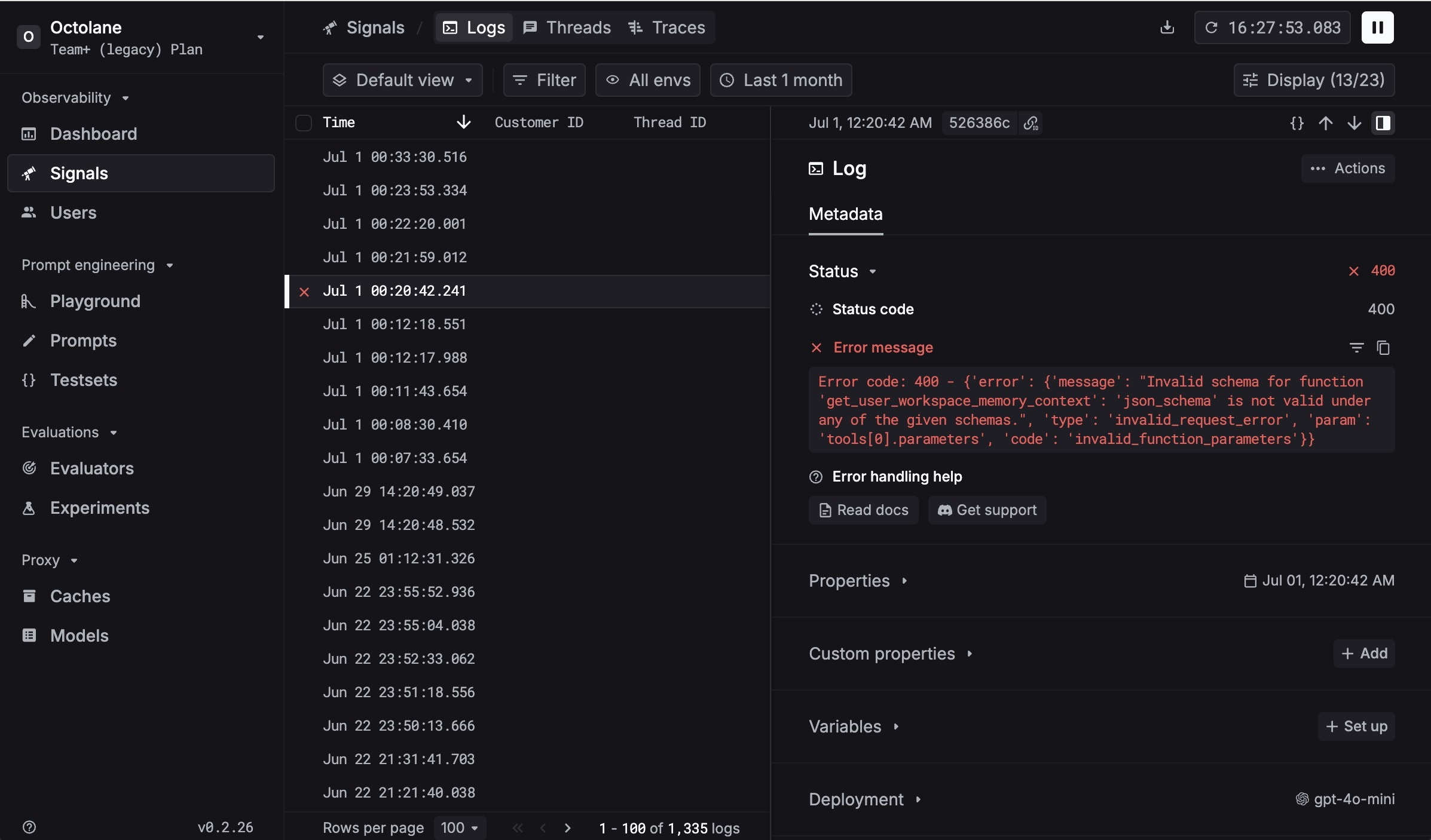
In this view, the team is inspecting a failed LLM call with full visibility - status codes, error messages, parameters, and traces - all in one place. Instead of manually backtracking issues, they can pinpoint bugs instantly and get back to shipping.
This kind of real-time observability has become part of Octolane's everyday workflow, powering a faster, more reliable AI product.
Changes: From Blindspots to Full Visibility
| Before Respan | After Respan |
|---|---|
| Prompt bugs hard to trace | Full input/output logging per LLM call |
| Devs re-ran sessions manually | Auto debugging with error tagging |
| No visibility into model costs | Token + cost breakdown by prompt |
| Slack pings from users when AI failed | Proactive alerts sent to engineering |
| No version history for prompts | Prompt diffs tracked over time |
| Latency issues surfaced too late | Slow calls flagged in real-time |
| Debugging blocked shipping | Teams shipped AI column + Action Mode faster |
This removed the guesswork. Instead of re-running sessions to trace bugs, the team could resolve issues in minutes, and get back to building.
Results: Faster Debugging, Faster Shipping
Since integrating Respan:
- LLM debugging time dropped 90%
- Feature velocity doubled
- AI column and Action Mode shipped with confidence
"With Respan, we can move 10x faster. Our AI is smarter, our product is more reliable, and our team never has to guess what the model is doing."
- One Chowdhury, CEO, Octolane AI