Overview
Every span has alog_type field that determines its input/output format. The most common type is chat, but Respan supports logging embeddings, audio, tool calls, and workflow spans.
All span types use universal input and output fields and are sent to the same logging endpoint. For the complete field reference, see Span fields & parameters.
All span types
- LLM inference
- Workflow & agent
- Other
| Span type | Description | Input | Output |
|---|---|---|---|
chat | Chat completions (default) | Messages array | Assistant message |
completion | Legacy completion format | Prompt string | Completion string |
response | Response API calls | Request object | Response object |
embedding | Vector embeddings | Text string | Embeddings array |
transcription | Speech-to-text | Audio metadata | Transcribed text |
speech | Text-to-speech | Text string | Audio metadata |
Chat
The default span type. Input is an array of messages, output is the assistant’s response.Images
Include images in your messages using theimage_url content type. This follows the same format as the OpenAI vision API.
detail parameter can be auto, low, or high.
Thinking blocks
When using models with thinking capabilities (e.g. Claude with extended thinking), the response includes additional reasoning fields that are automatically captured. Request:Prompt variables
Pass prompt variables so they appear in the side panel for easy inspection and can be added to testsets with one click.{{}} in your input and pass a variables object:
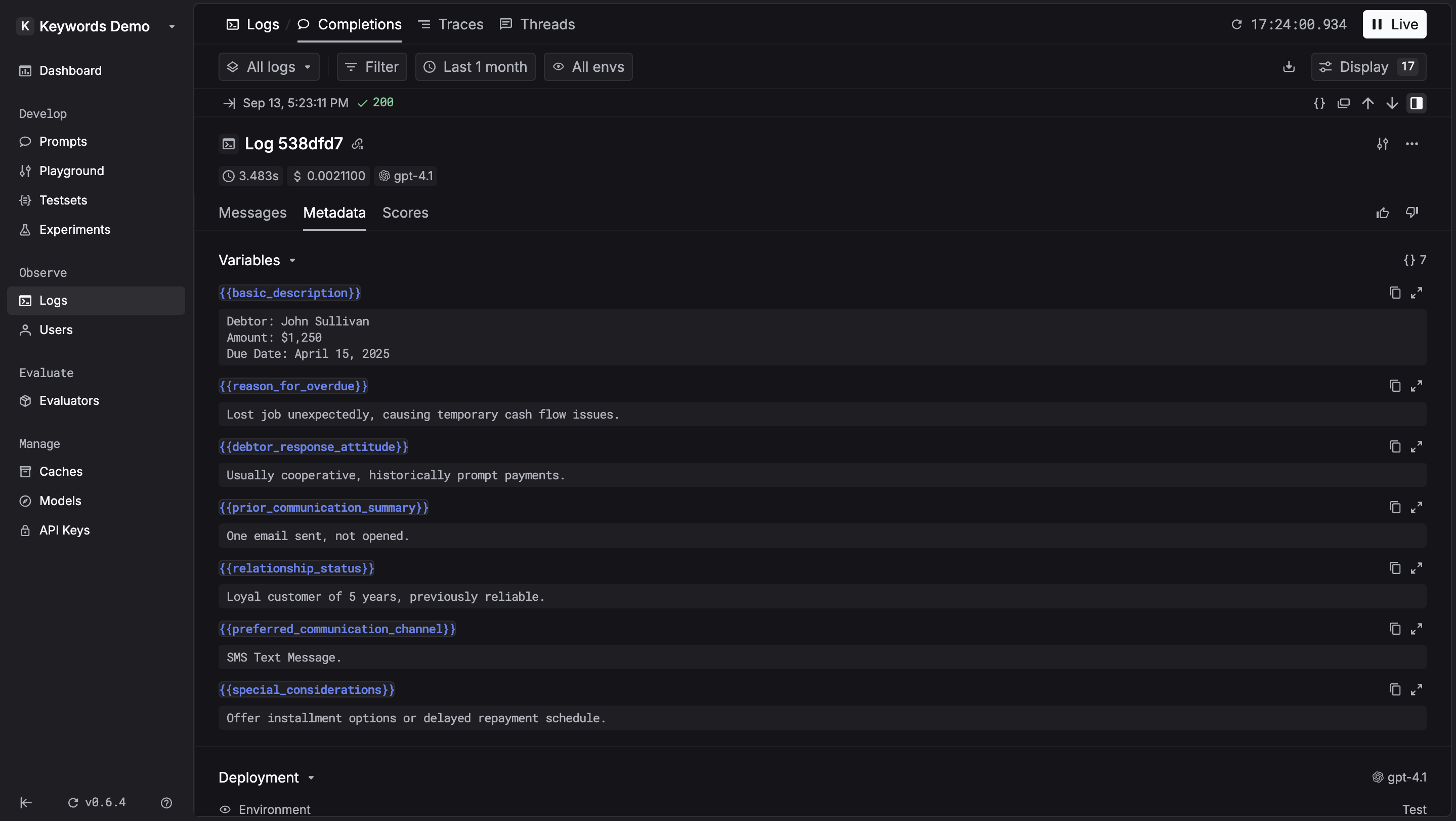
If you are using prompts via the LLM Gateway, variables are logged automatically — no need to pass them manually.
Tool calls
Record tool calls and function calling interactions as part of chat messages:tool_callsin the assistant message — array of function calls madetoolsat the top level — array of available function definitionstool_choice(optional) — specify which tool the model should use
Embedding
Setlog_type to "embedding". Input is text, output is the vector array.
Speech & transcription
Transcription (speech-to-text)
Setlog_type to "transcription". Input is audio metadata, output is transcribed text.
Speech (text-to-speech)
Setlog_type to "speech". Input is text, output is audio metadata.
Workflow & agent types
These span types are used by tracing to represent spans in a trace hierarchy:workflow— Root-level workflow orchestrationtask— Individual task within a workflowtool— Tool or function executionagent— AI agent operationhandoff— Agent-to-agent transferguardrail— Safety and validation check