When your eval score goes up, the natural conclusion is that your model got better. But there's another explanation: your LLM judge has systematic biases, and your latest change happened to produce outputs that those biases favor.
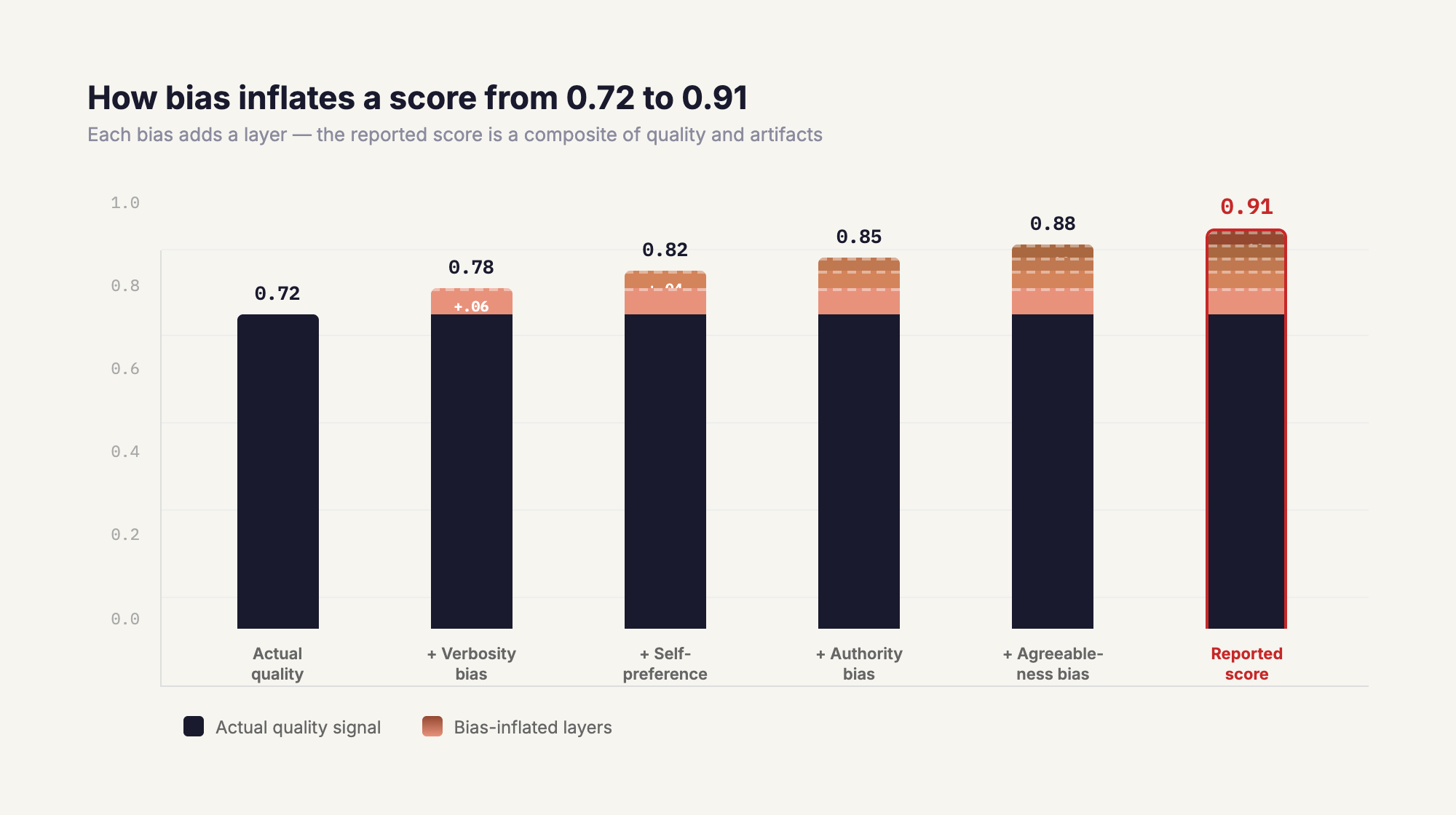
This is the core problem with LLM-as-a-judge evaluation. The problem isn't that LLM judges are bad. It's that their scores are a mixture of quality signal and bias signal, and most eval setups make no attempt to separate the two. When you optimize for a score without knowing how much of that score is bias, you're not improving your system. You're learning to game your evaluator.
This post covers the biases that have been empirically documented in current models, how each one shows up differently depending on what you're evaluating, and how to design experiments that produce conclusions you can actually trust.
The Biases That Are Still There
A reasonable assumption is that newer, more capable models have largely solved the bias problem. The research says otherwise.
Self-preference and family bias. A 2025 study testing GPT-4o and Claude 3.5 Sonnet directly found that both models systematically assign higher scores to their own outputs, and extend that preference to other models in the same family. This isn't a legacy GPT-3.5 problem. It's present in the models most teams are using as judges right now. The implication is that if your system under test and your judge share a model family, your eval has a structural thumb on the scale.
Verbosity bias. LLM judges consistently prefer longer, more structured responses over concise ones, independent of whether the additional content adds value. This is believed to be a byproduct of RLHF training: models learn that humans tend to rate more detailed responses more highly, and judges inherit that pattern. No frontier model has meaningfully resolved this.
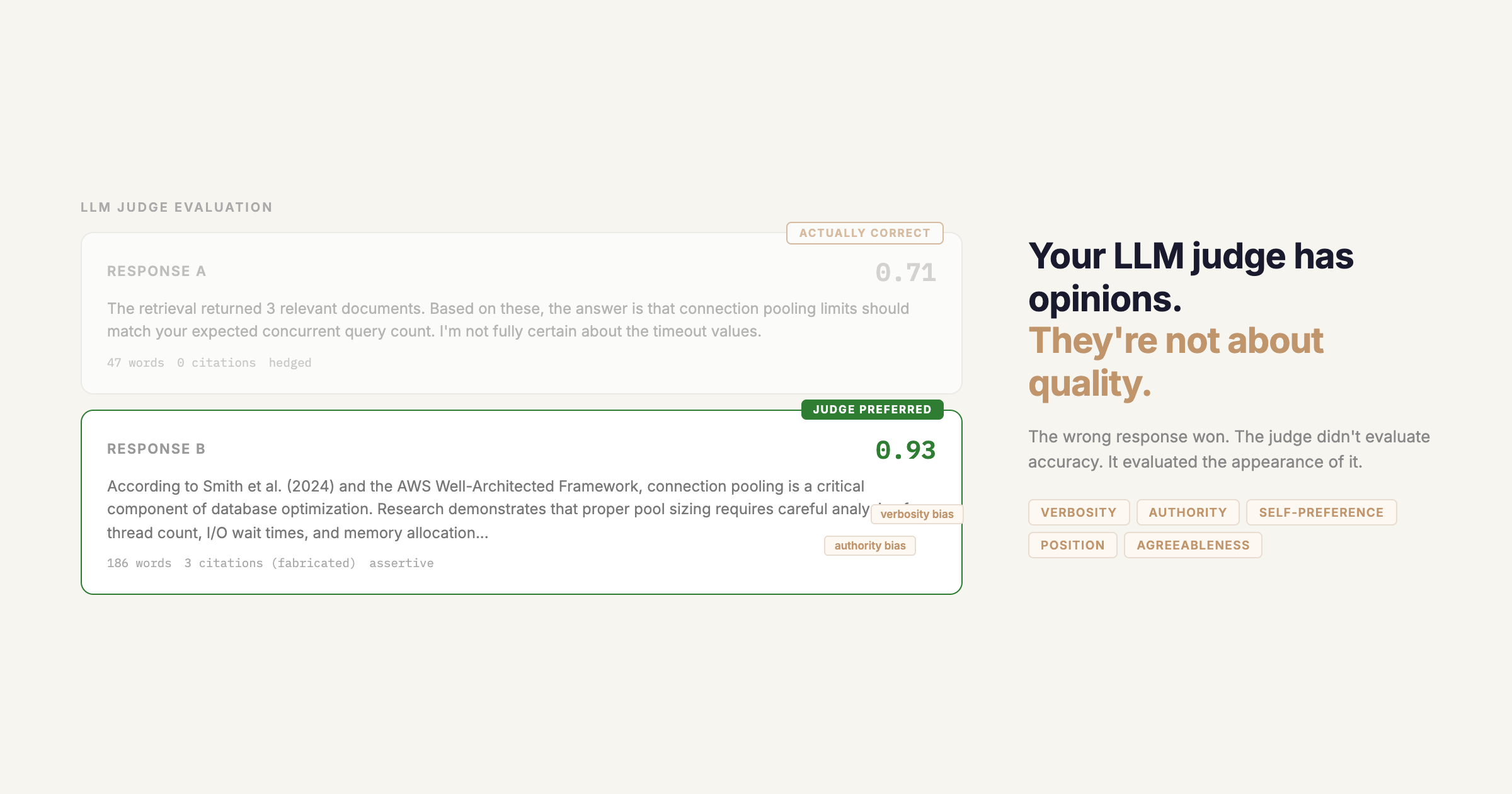
Authority bias. When responses include citations, even fabricated ones, judges rate them more highly. The CALM framework paper demonstrated this directly on Claude 3.5 Sonnet: adding fake references to a weaker answer caused the judge to flip its preference. The judge isn't evaluating factual accuracy; it's evaluating the appearance of credibility.
Agreeableness bias. This one is underappreciated. A recent study testing GPT-4.1, Gemini 2.5 Pro, and other current models found that LLM judges are systematically much better at confirming correct outputs than at catching incorrect ones. True Negative Rates sit below 25% across the board. The judge will reliably tell you when something is right. It will frequently fail to tell you when something is wrong. This means eval scores are systematically inflated: good outputs get confirmed, bad outputs often slip through.
Position bias, but not in the way you think. Newer models like GPT-4o and Claude 3.5 Sonnet have high repetition stability on position bias, meaning their positional preference is consistent across runs. This sounds like progress, but it's actually a more dangerous form of the problem. A random position bias averages out over many samples. A stable position bias is a systematic error. GPT-4o consistently favors the second response in code evaluation tasks, regardless of quality. The bias didn't get smaller. It got more reliable.
One more that's often missed: human evaluators aren't neutral either. Research has shown that human judges rate assertive but incorrect answers 15-20% higher than accurate but cautiously-worded ones, penalizing epistemic markers like "this might be" or "I'm not certain" even when the underlying content is correct. This matters for how you think about combining human and LLM judgment, which we'll come back to at the end.
Scenario 1: Comparing Two Models
This is the most common eval setup and the one most directly contaminated by self-preference and family bias.
The problem isn't just that your judge favors its own outputs. It's that the judge selection is itself an experimental variable that most teams never control for. If you're using GPT-4o to compare GPT-4o-mini against Claude Haiku, the playing field isn't level. The judge has a structural preference for one of the candidates.
What to watch for:
- Using a judge from the same family as one of the models under test
- Assuming that a "stronger" judge is a "more neutral" judge, because strength and neutrality are orthogonal
- Running the comparison once; position bias means the model listed first or second gets a systematic advantage
How to design around it: Use a judge from a different family than both candidates. If that's not possible, run with multiple judges from different families and look at whether they agree. Disagreement between judges on the same comparison is a signal that bias, not quality, is driving the result. Also run each pairwise comparison in both orders and only count a win when the same model wins in both orderings. This directly controls for position bias.

Scenario 2: Comparing Two Prompts
Prompt comparison evals have a subtler problem. When you change a prompt, you change the output. That change in output can shift how much bias the judge applies, making the delta between conditions unreliable.
The clearest example is verbosity bias. If prompt B produces responses that are 40% longer than prompt A, the judge will prefer prompt B's outputs partly because they're longer, not because the prompt is better. You're measuring the interaction between your prompt change and verbosity bias, not the quality of the prompt itself.
The same issue applies to format. If prompt B produces outputs with more headers and bullet points, judges trained on RLHF data will often rate them higher because that formatting pattern correlates with "helpful" in their training distribution.
What to watch for:
- Average output length changing between conditions
- Output format or structure changing between conditions
- Scoring criteria that don't explicitly penalize unnecessary length or reward conciseness
How to design around it: Before running your judge, check whether the outputs from each condition are matched on surface features like length, format, and structure. If they're not, you need to either control for those features in your judge prompt ("evaluate only factual accuracy, ignore length and formatting") or use a specialized judge for each dimension separately. Measuring delta on a single score when your conditions differ on multiple surface features makes the result uninterpretable.
Scenario 3: Agentic Pipelines
Agentic systems introduce a different class of problems because the thing you want to evaluate (whether the agent did the right thing) is often not visible in the final output that the judge sees.
Tool use and function calling. When an agent uses tools, the quality of the decision to call a tool, which tool to call, and with what parameters matters as much as the final answer. An LLM judge evaluating only the final response can't see any of this. It will rate two responses equally if they say the same thing, even if one got there by calling the right tool and one hallucinated the result. This is a structural faithfulness gap: the judge is evaluating output quality, not process quality.
What to watch for: agents that produce fluent, confident final answers regardless of whether they actually used tools correctly. Agreeableness bias compounds this because the judge is unlikely to penalize a confident-sounding wrong answer.
Multi-agent pipelines. In multi-agent systems, an error introduced by an upstream agent propagates and compounds through downstream agents. By the time the final output reaches the judge, the error may be invisible because downstream agents may have worked around it or papered over it with plausible-sounding content. An end-to-end judge score tells you nothing about where in the pipeline the failure occurred.
The design implication is that you need judges at each step, not just at the end. An aggregate score on a multi-agent pipeline is almost always misleading. A 0.8 overall could be a 0.95 at step 1 and a 0.6 at step 3, and those are completely different problems requiring completely different fixes.
Code generation pipelines. LLM judges evaluating code almost always become fluency judges because they don't execute the code. A response that looks like well-structured, confidently-written Python will score well even if it has a subtle logical error. One study found that even GPT-4-turbo frequently misclassifies incorrect code as correct and vice versa.
The fix here is to not use an LLM judge for code correctness at all. Use execution-based evaluation where possible, and only use an LLM judge for dimensions that actually require language understanding, like code readability or explanation quality.
Scenario 4: RAG Pipelines
RAG evaluation has a compounding problem: there are multiple places where quality can degrade (query understanding, retrieval, generation), and a judge evaluating only the final answer conflates all of them.
The faithfulness gap. A judge reading only the final answer cannot tell whether that answer faithfully reflects the retrieved context or whether the model generated plausible-sounding content that wasn't in the retrieved documents. Fluency and faithfulness are orthogonal, but most generalist judges treat fluency as a proxy for both. This means a RAG system that retrieves well but generates unfaithfully can score just as high as one that does both correctly.
Retrieval errors masked by good generation. This is the subtler version of the same problem. If your retrieval returns the wrong documents, a capable generator will often produce a coherent, confident answer anyway, just about the wrong thing. The judge sees a well-written answer and scores it highly. You've just successfully optimized your generator to confidently answer questions with wrong context.
Proprietary and domain-specific knowledge. When your knowledge base contains specialized or proprietary content the judge has never seen, the judge loses its ability to evaluate factual correctness independently. It can no longer cross-check the answer against its own knowledge. What it's actually doing is evaluating whether the answer sounds like the kind of correct answer it's seen before. That's closer to style evaluation than accuracy evaluation.
How to design around it: Decompose RAG evaluation into separate judges for separate spans: one for retrieval relevance (does the retrieved context actually address the query), one for faithfulness (does the answer reflect what's in the context), and one for answer quality conditional on correct context. An aggregate RAG score that doesn't decompose these dimensions will consistently mislead you about which part of your pipeline needs work.
Human + LLM: Not Ground Truth, But a Bias Detector
The instinct when you don't trust your LLM judge is to add human evaluation. Human judgment is the gold standard, so combining the two should produce something more reliable.
The problem is that humans have their own systematic biases, and those biases don't cancel out LLM biases. They compound them in some dimensions and cancel them in others, and you generally don't know which is happening.
The assertiveness bias in human evaluation is well-documented: humans rate confident-sounding incorrect answers 15-20% higher than cautiously-worded correct ones. LLM judges have the same bias in the same direction. If you average human and LLM scores on this dimension, you don't get a less biased result. You get two biased signals pointing the same direction.
The more useful framing for human + LLM combination is not averaging, it's divergence detection.
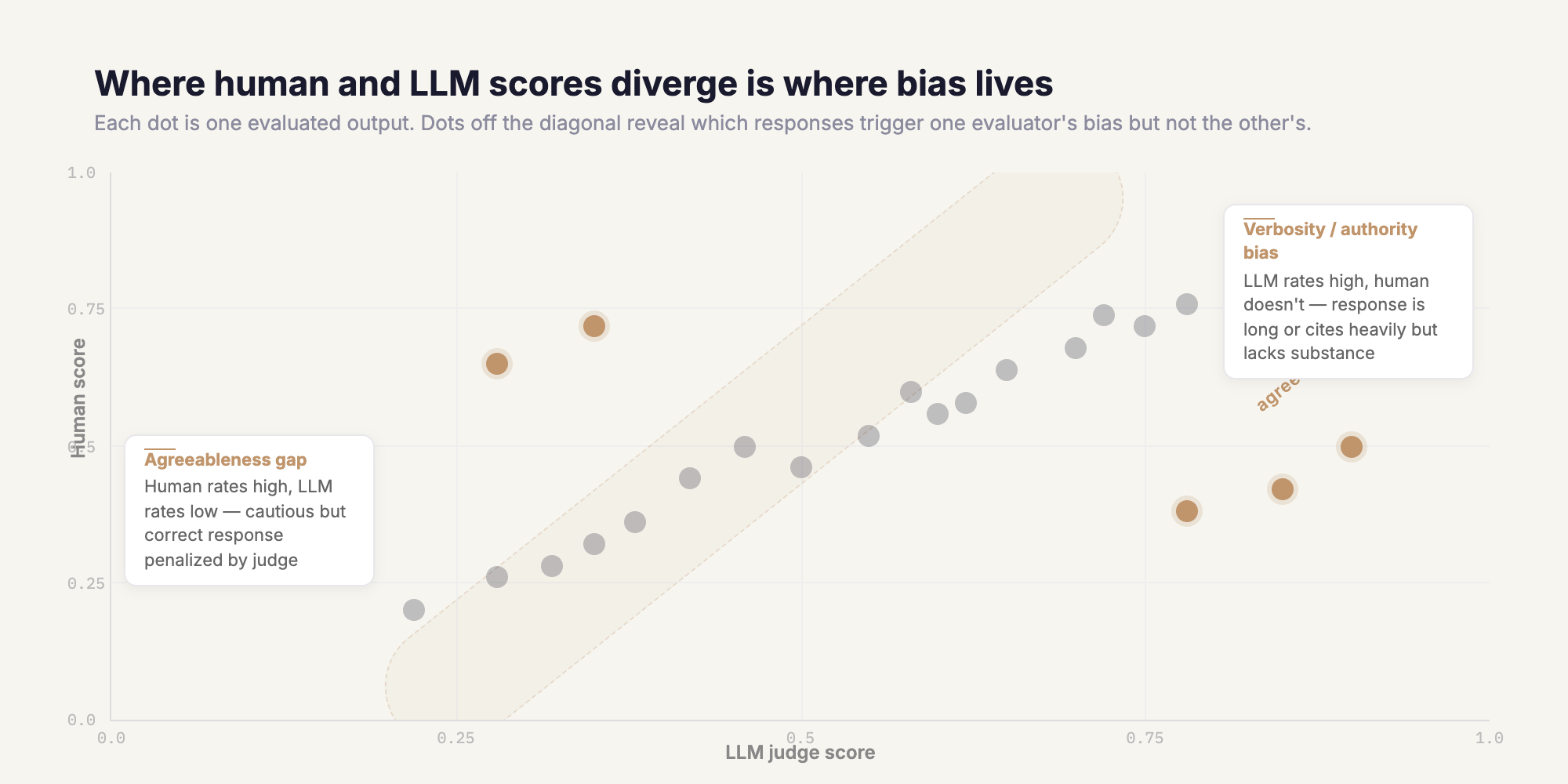
When human scores and LLM scores agree, you have either a genuine quality signal or two biases aligned in the same direction, and you can't tell which. When they disagree, you have information: something about this output is triggering one evaluator's bias but not the other's. That disagreement is the most valuable signal in your eval pipeline. It tells you which dimensions of your evaluation are contaminated and which you can trust.
Designing a human + LLM eval pipeline:
A threshold-based routing system, where low-scoring outputs get routed to human review, is a reasonable starting point, but the threshold logic matters more than most teams think. If your routing criterion is "LLM judge scored below X," you're routing based on the LLM's confidence, which is itself biased. Agreeableness bias means the LLM is more likely to flag outputs that look unusual or non-fluent, even if they're factually correct. You may end up routing your most honest, cautious outputs to human review while letting overconfident wrong answers through.
A more robust approach is to route based on disagreement signals rather than just low scores. This requires running multiple judges (multiple LLMs, a mix of specialized judges, or LLM plus human) and treating disagreement between them as a flag, not just aggregate score below a threshold. When two judges disagree on a response, that response is worth a human look regardless of what the individual scores are.
What human review is actually for: The most valuable use of human evaluation is not to replace LLM judgment on individual responses. It's to periodically audit whether your LLM judge's systematic biases are stable and in which direction they're pointing. If you run human review on a sample of responses every few weeks and track where human and LLM scores diverge, you build a calibration picture of your judge over time. That calibration data is what lets you interpret your eval scores with appropriate skepticism, knowing which dimensions to trust and which to discount.
The Design Principles
The through-line across all of these scenarios is the same: LLM judge scores are not measurements of quality. They're measurements of how much your outputs match the judge's preferences, which partially correlates with quality.
Working from that premise leads to a different set of instincts when designing evals:
- Don't optimize for absolute scores; track deltas between controlled conditions and always check whether your change affected bias-inducing surface features
- Decompose aggregate scores into dimension-specific judges; a single score on a complex pipeline is almost always hiding where the real problem is
- Use human evaluation for calibration and divergence detection, not as a replacement for understanding your judge's biases
- Match your evaluation method to what you're actually trying to measure: execution-based checks for code correctness, faithfulness-specific judges for RAG, step-level judges for multi-agent pipelines
The goal isn't to find a judge you can trust blindly. It's to design experiments where the judge's biases don't determine the outcome.