OpenTelemetry is the right foundation for LLM observability. We believe that. We've built Respan on it. But if you've actually tried to instrument an LLM application using OTel's semantic conventions, you know the experience ranges from "workable with caveats" to "what is this."
And if you've tried to trace a CLI tool (Claude Code, Codex, aider, or anything else that runs in a terminal), the experience gets meaningfully worse. CLI tools don't have servers, don't have HTTP request lifecycles, and don't fit the mental model that OTel was designed around.
This post is an honest accounting of where OTel's GenAI semantic conventions stand today, where they fall short, and what we've had to build around to make tracing actually work for CLI-based AI tools.
The state of GenAI semantic conventions
OTel's semantic conventions for generative AI were promoted to "development" status in late 2025. That sounds like progress, but "development" in OTel's maturity model means "the schema exists and may change." It's one step above "experimental." The conventions for HTTP, databases, and messaging have been stable for years. GenAI is still figuring out what fields matter.
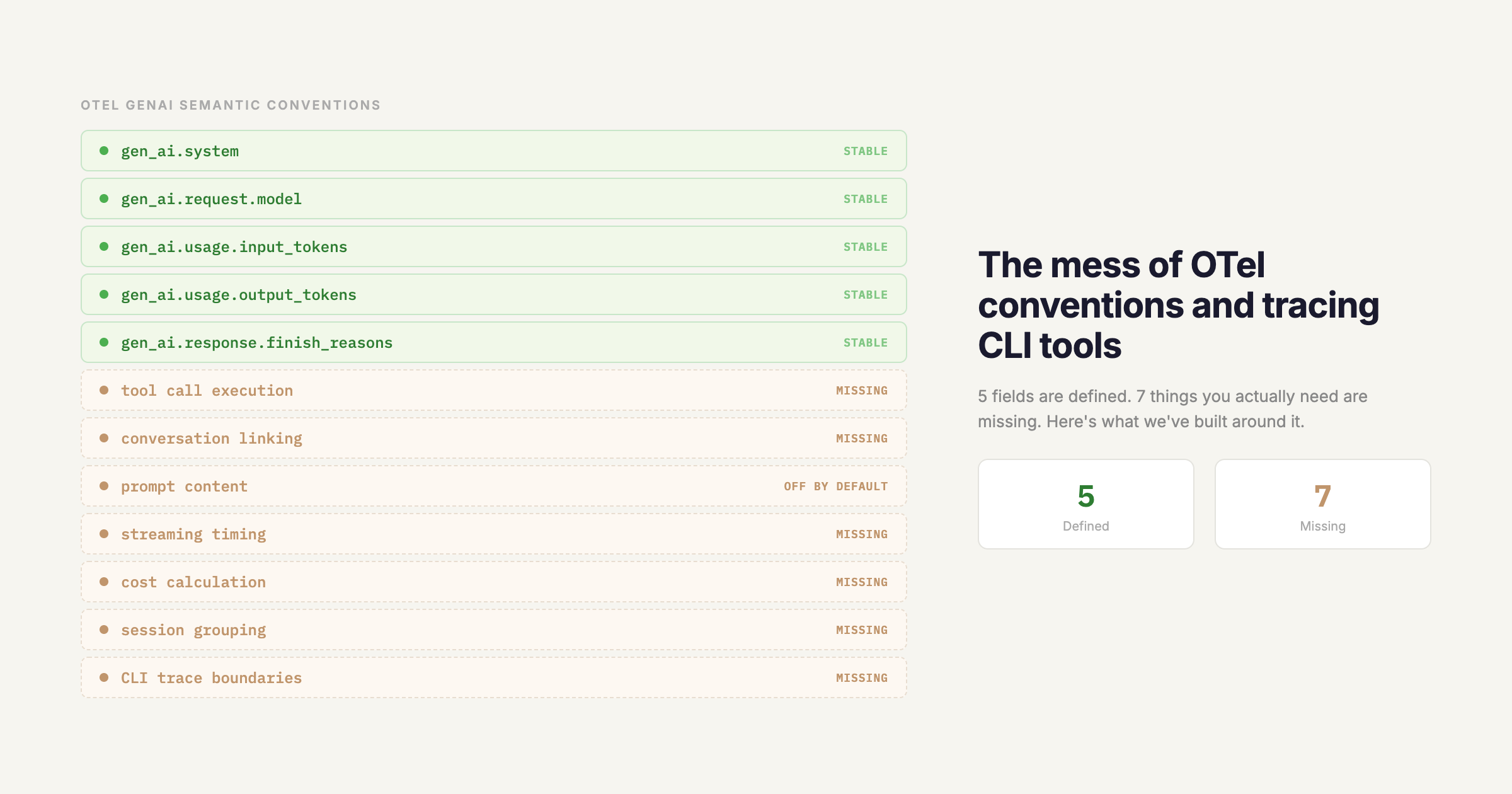
Here's what's actually defined and mostly works:
gen_ai.system: the provider (openai, anthropic, etc.)gen_ai.request.model: the model IDgen_ai.usage.input_tokensandgen_ai.usage.output_tokens: token countsgen_ai.response.finish_reasons: why the model stopped generating
This covers the basics of "I made an LLM call." It does not cover most of what you actually need to debug an LLM application.
What's missing
Tool calls. The conventions have no standard way to represent tool/function calls. If your agent calls a tool, you can record that a tool call happened in the completion, but there's no semantic convention for the tool's execution span: its name, its arguments, its result, whether it succeeded or failed. Every instrumentation library invents its own schema for this. If you're stitching together traces from two different libraries, their tool call spans won't be compatible.
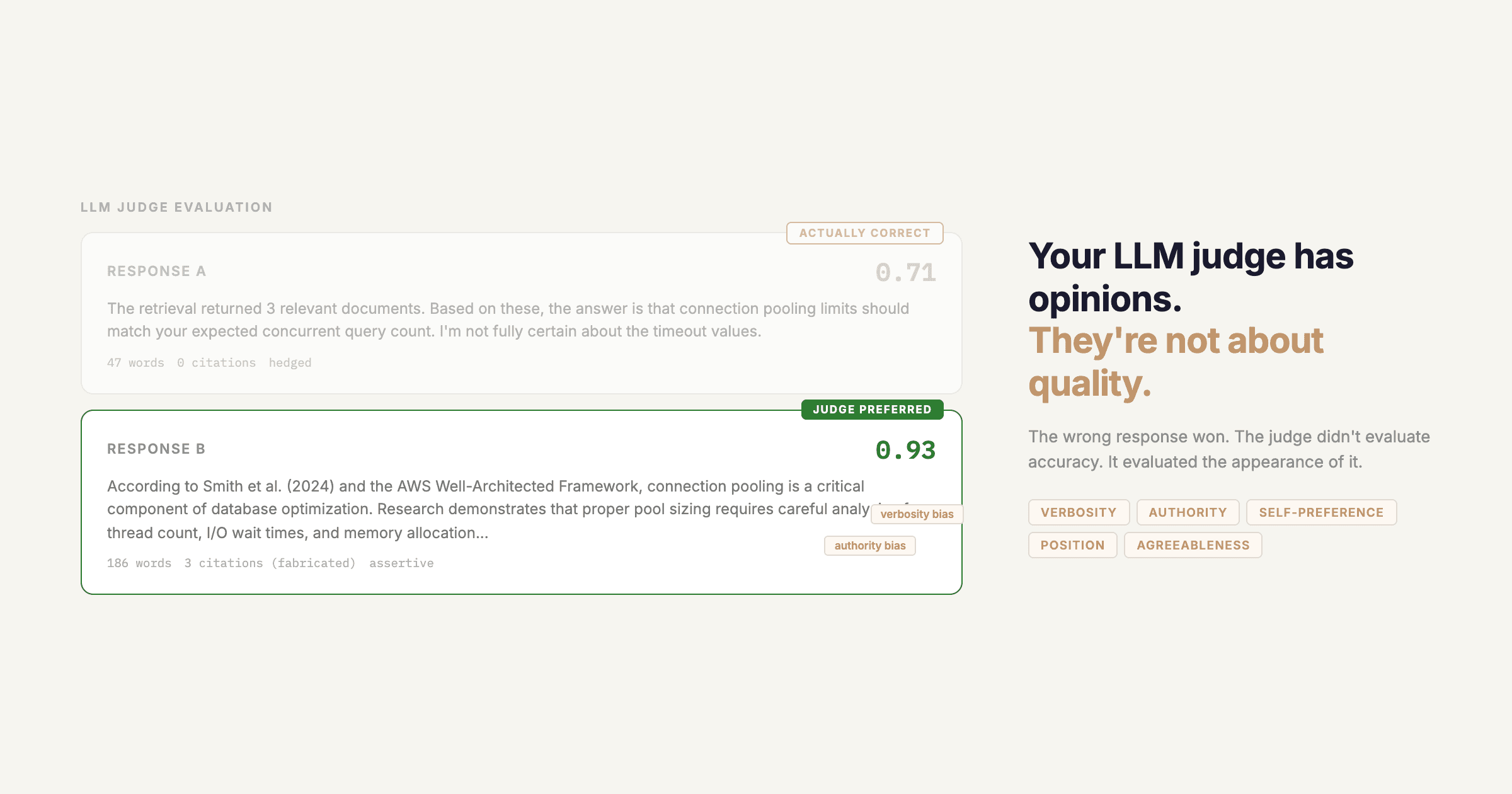
Conversation structure. There's gen_ai.prompt and gen_ai.completion as event attributes, but the spec explicitly says prompt content capture is optional and should be off by default for privacy. Fair enough, but it means that by default, your traces show token counts without any way to understand what those tokens were. You can see that a call used 4,000 input tokens. You can't see why.
Multi-turn context. The conventions treat each LLM call as independent. There's no standard way to link a sequence of calls into a conversation or session. For chat applications, this is annoying. For agentic loops, where the same model is called repeatedly with an accumulating context window, it makes it nearly impossible to understand the agent's reasoning trajectory from traces alone.
Streaming. When a model streams its response, the conventions don't specify whether you create one span for the full stream or one span per chunk. Most implementations create a single span with the final token counts, which means you lose all timing information about when tokens arrived. For latency debugging ("why did the user see nothing for 3 seconds, then a burst of text"), the traces are useless.
Cost. There's no gen_ai.usage.cost attribute. Token counts are there, but cost requires knowing the per-token price for the specific model, which varies by provider and changes over time. Everyone who wants cost tracking has to implement their own price lookup table. This is the single most-requested feature in every LLM observability tool, and the semantic conventions punt on it entirely.
CLI tools make everything harder
Web applications have a natural trace structure: a request comes in, work happens, a response goes out. The trace root is the request. Child spans are the work. This maps cleanly onto OTel's span model.
CLI tools don't have this. A CLI session might last 30 seconds or 30 minutes. It might make 2 LLM calls or 200. The "request" is the user typing a command, but there's no HTTP request to attach a trace to. The "response" is whatever appears in the terminal, but it's not a single response. It's an ongoing stream of actions and outputs.
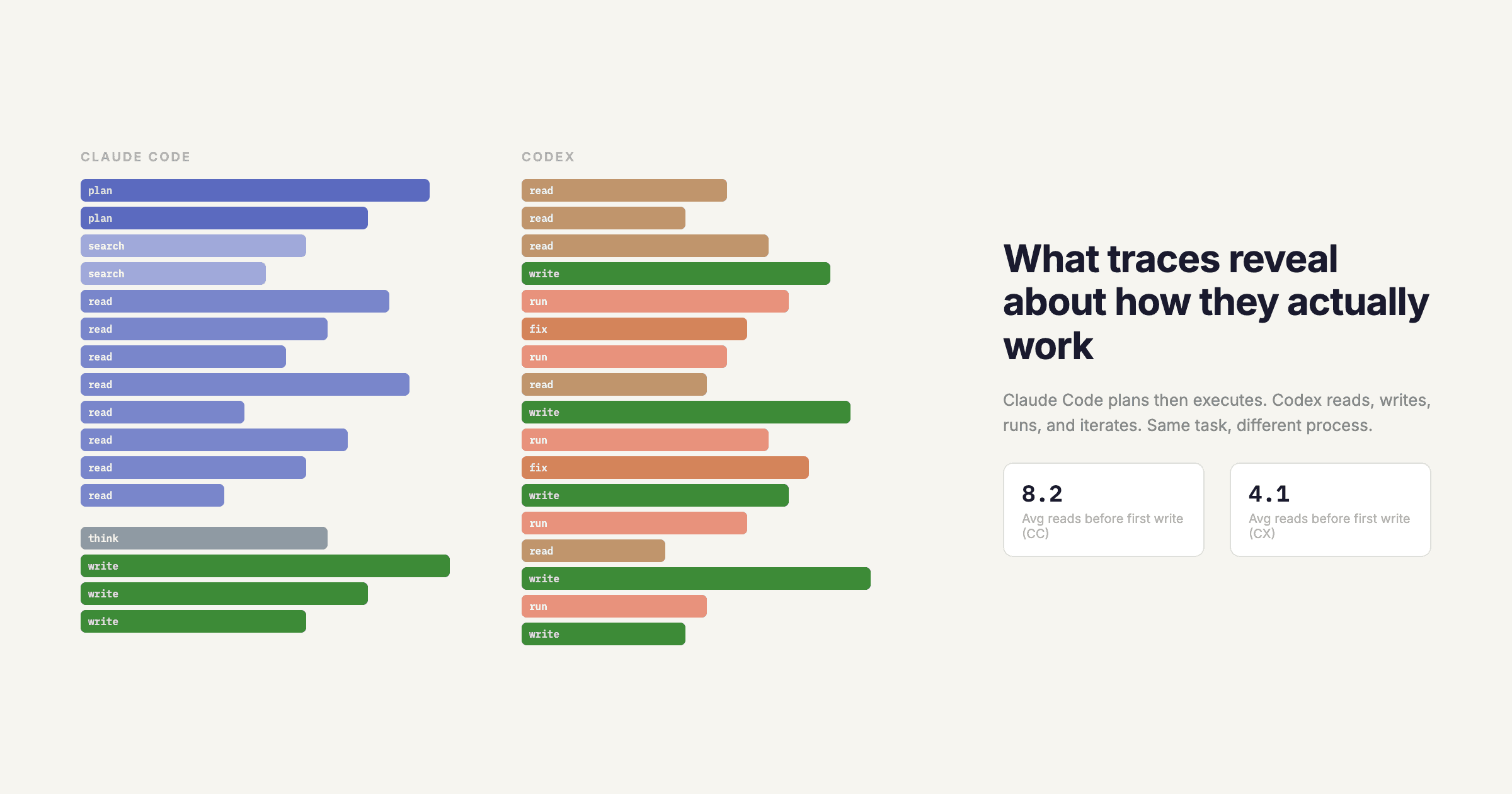
Problem 1: What's a trace? In a web app, one trace = one request. In a CLI tool, what's the trace boundary? One user message? One complete task? The entire session? Different tools make different choices, and there's no convention to guide them. Claude Code treats each user message as a trace. Aider treats the entire session as a trace. Neither is wrong, but they produce fundamentally different trace structures that can't be meaningfully compared.
Problem 2: No server means no automatic instrumentation. OTel's auto-instrumentation works by hooking into HTTP servers, database drivers, and message queues. CLI tools don't use any of these in the standard way. If you want traces from a CLI tool, someone has to manually instrument it, or you have to wrap the LLM client library, which brings its own problems (version compatibility, monkey-patching, missing calls through direct HTTP).
Problem 3: Long-running spans. OTel exporters are designed around the assumption that spans are short-lived, seconds or maybe minutes. A CLI agent session can run for an hour. Some exporters buffer spans in memory until the trace completes. If the CLI tool is killed (Ctrl+C, terminal closed, laptop lid shut), those buffered spans are lost. You get partial traces or no traces at all.
Problem 4: Local-only execution. Web apps export traces to a collector running alongside the application. CLI tools run on the developer's machine. That means traces either need to be exported over the internet to a remote collector (adding latency to every span export, which users notice) or buffered locally and batch-exported (which means traces don't appear in your dashboard until the session ends or a flush interval fires).
What we've done about it
We've dealt with all of these at Respan, and our solutions are pragmatic rather than elegant. Here's what actually works:
Extended attributes. We define additional span attributes beyond the OTel conventions: respan.tool.name, respan.tool.arguments, respan.tool.result, respan.session.id, respan.conversation.turn. These aren't standard, but they're consistent across all Respan-instrumented applications. When the OTel conventions eventually define standard attributes for these, we'll migrate. Until then, data that exists in a non-standard schema is better than data that doesn't exist.
Session-based trace grouping. Instead of trying to fit CLI sessions into the one-trace-per-request model, we use a session ID that links related traces together. Each user message starts a new trace, but all traces in a session share a respan.session.id attribute. This lets you view an entire CLI session as a connected sequence without forcing it into a single monolithic trace.
Eager span export. Our SDK exports spans as soon as they complete, not when the trace completes. This means partial traces show up in the dashboard in real-time, so if the CLI tool crashes, you still have everything up to the crash. We use a lightweight background thread for export so it doesn't add perceptible latency to the tool's operation.
Prompt capture with controls. We capture prompt content by default (opt-out, not opt-in), because traces without prompt content are nearly useless for debugging. But we provide granular controls: you can redact specific fields, hash PII, or disable capture entirely. The OTel convention's default-off approach is the safe choice for a generic standard. For a purpose-built LLM observability tool, it's the wrong default.
Cost calculation. We maintain a pricing table for all major model providers, updated weekly. When a span includes gen_ai.request.model and token counts, we calculate and attach the cost automatically. It's not in the semantic conventions, so we do it ourselves.
Where this is going
The OTel GenAI working group is active. There are open PRs for tool call conventions, multi-turn linking, and streaming semantics. The trajectory is toward covering the gaps described here, probably within the next 6 to 12 months.
But the pace of LLM tooling development is faster than the pace of standards development. By the time the conventions stabilize, the ecosystem will have moved on to new patterns (multi-agent orchestration, computer use, real-time voice) that the conventions don't cover yet.
The practical implication is that if you're building LLM observability today, you can't wait for the standards. You need a foundation that's OTel-compatible so you benefit from the ecosystem and can adopt conventions as they mature, but that extends beyond the conventions where they fall short. That's the design philosophy behind Respan's SDK, and it's why we're opinionated about things the spec is deliberately silent on.
The mess of OTel conventions isn't a reason to avoid OTel. It's a reason to use a tool that handles the mess for you.